目前常见的Web反采集策略大概有以下几种:
- 1)数据加密;
- 2)限制访问频率;
- 3)数据以非文本形式展现;
- 4)验证码保护;
- 5)Cookie验证;
本文主要探讨一下如何突破”限制访问频率”:
“限制访问频率”的原理:
服务器端程序(例如,WAF)维护了一个客户端(IP)的访问计数,如果客户端(IP)请求频率超过阈值,请求就会被拦截,通常会出现下列情形:
- 1)最常见的:返回403或503错误。
- 2)连接被重置。
- 3)最令人头疼的:返回无效的内容
突破方法:
- 1)使用HTTP代理。因为服务端是根据IP进行限制的,通过使用代理就可以将下载量平均到多个IP上。需要注意的是透明代理往往是无效的,因为WAF能够检测到真实的源IP,所以要使用隐秘(secret)代理。
- 2)增加请求延迟。比如,WAF限制单IP请求频率不能超过20次/分钟,我们可以在两次请求之间增加5S的延迟,这样下载频率就是12次/分钟,就不会被拦截了。
通常我们会将1)和2)的方法结合,这样即能防止被拦截,又能加快采集速度。例如,使用10个代理,每次下载增加5S延迟,一分钟的实际下载量就是:120次。
- 3)利用搜索引擎缓存(Google,Bing,百度)。“曲线救国”策略,绕过目标服务器,从搜索引擎的缓存进行采集。而且缓存里的页面的结构和原页面是一样的,不用重写提取规则。
- 4)谷歌翻译。让谷歌作为我们的“代理”,将源语言和目标语言都设置成一样,这样从谷歌翻译结果获取的数据和原页面就是一样的(注意,HTML结构有很大变化,需要重写提取规则)。
- 5)对于返回无效内容的情况,一定要找到检测内容是否有效的方法,否则很难保证所有数据都是正确的。
例如,
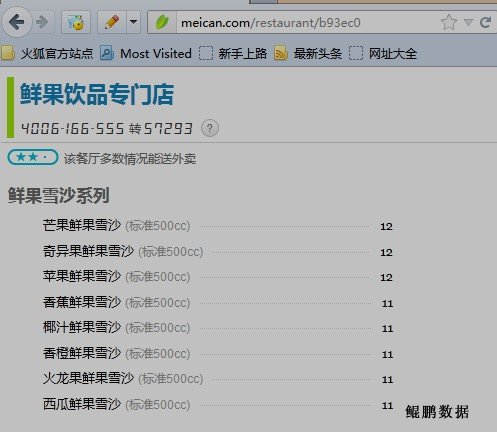
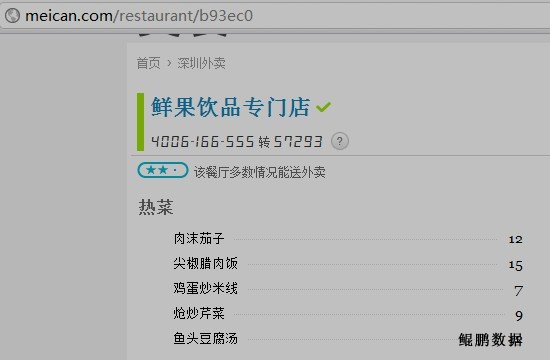
美餐网的菜单,如果采集过快返回的菜单项目就是随机的,如下图所示:
上图是正常数据
上图是无效数据
鲲鹏数据的技术人员通过仔细分析页面源码,最后发现了规律:正常页面的菜单项ID基本上都是连续的,而随机内容的菜单项ID是随机的。
基于这一特征我们就能用程序检测出返回的内容是否有效,只处理有效的数据,无效的内容进行重新采集。